Sesgo en la IA
Según una nueva investigación encargada por Qlik, que encuestó a más de 2.000 ciudadanos del Reino Unido, el "debate sobre la IA" ha pasado de los temores por la pérdida de empleo a un nuevo debate sobre el papel de los seres humanos en la programación de la IA, el potencial de sesgo y dónde debería estar la rendición de cuentas para aliviar ese sesgo. Más de un tercio (41%) de los encuestados afirmaron que la IA en su estado actual está sesgada y, como resultado, están preocupados por su impacto. Sin embargo, hay una idea errónea entre el público del Reino Unido de que es el análisis humano o la mala interpretación de los datos (en lugar de los datos en sí mismos), lo que puede causar tal sesgo. Después de todo, los datos proporcionan sustento a la IA, incluyendo su capacidad de aprender a un ritmo mucho más rápido que el de los humanos. Y los datos que los sistemas de IA utilizan como entrada pueden tener sesgos ocultos.
Causas de los sesgos ocultos
El sesgo es a menudo causado por conjuntos de datos incompletos, y quizás lo más importante, por la falta de contexto en torno a esos conjuntos de datos. Por ejemplo, cuando hacemos una pregunta como humanos, la hacemos basándonos en una hipótesis, lo que hace que esa pregunta esté intrínsecamente sesgada desde el principio. Por eso, la IA tiene que tener la capacidad de tener un contexto `integrado' para analizar todos los datos en nombre de los seres humanos y proporcionar resultados más objetivos.
Me gustaría darles un ejemplo de Word War II que muestra cómo los datos incompletos pueden causar resultados sesgados.
Durante la Segunda Guerra Mundial, el matemático húngaro Abraham Wald realizó un estudio con el Ministerio del Aire Británico para utilizar análisis estadísticos que ayuden a proteger a los bombarderos que vuelan sobre territorio enemigo. Los datos que se iban a analizar incluían el número y la ubicación de los agujeros de bala en los aviones que regresaban, y el objetivo era utilizar esta información para determinar dónde se podía añadir armadura a la estructura del avión de la mejor manera posible.
Esta información fue presentada visualmente para comprender mejor los datos, mostrando dónde se encontraba el número máximo de agujeros de bala en los aviones que regresaban.
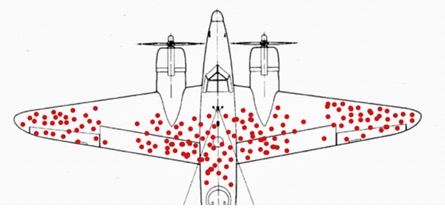
Esta tabla mostraba los mayores daños no en el ala principal y en los largueros de la cola, los motores y el núcleo del fuselaje, sino en las extremidades de la aeronave. Basado en esto, el Ministerio del Aire sugirió agregar armadura a esas extremidades.
Pero Wald sugirió que estaban totalmente equivocados. Dijo que debería haber más armadura en los lugares que tuvieran menos agujeros, ya que se dio cuenta de que estaban olvidando que sus datos no incluían los aviones que se habían perdido. Si los aviones que regresaban no tenían agujeros en los largueros y motores de sus alas, la mejor suposición es que incluso unos pocos agujeros en esos lugares eran mortales: no se registraron daños en esas áreas porque esos aviones eran los que se habían estrellado. Wald recomendó más armadura en esas áreas "libres de datos".
La lección: los datos que no están ahí pueden contar una historia tan importante como los datos que sí están.
En Qlik, a menudo hablamos del poder de nuestra diferencia asociativa, que comprende todo el conjunto de datos para que los usuarios puedan ver lo que sucede y lo que no sucede en cualquier selección de datos. Esto a menudo puede incitar a los usuarios a hacer preguntas que tal vez no hayan pensado en hacer o a seguir caminos de investigación que tal vez no hayan comprendido que eran importantes. Si los datos de nuestro ejemplo de la Segunda Guerra Mundial se pusieran en Qlik, el análisis podría haberse visto así:
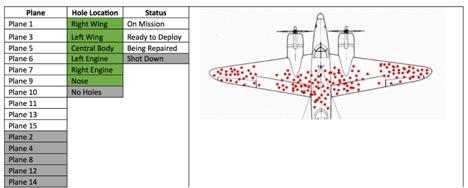
Al tener el contexto completo de los datos que se examinan y ver qué datos se excluyen, se puede entender rápidamente que los daños se concentran en las puntas de las alas y el cuerpo central y también que algunos aviones se excluyen de ese conjunto de datos. Específicamente, los aviones excluidos no tienen agujeros y/o fueron derribados (los datos en gris).
Esta poderosa diferencia asociativa única también permite a Qlik Cognitive Engine, el framework de Inteligencia Artificial de Qlik, aprender de todos los datos, con todo el contexto `integrado'.
Esta poderosa tecnología aumenta la visión periférica de nuestros usuarios, permitiéndoles obtener información al analizar el contexto completo de los datos en su nombre y evitar posibles sesgos en su análisis. Le sugiero que compruebe las capacidades del Motor Cognitivo Qlik, si aún no lo ha utilizado, y evite "cualquier agujero" en sus decisiones de negocio.

Comentarios para esta entrada
Sección en desarrollo...