La respuesta a mi presentación fue tal que decidí convertirla en un blog. Mi dirección formaba parte de la pista "Metadatos y calidad de los datos", por lo que la catalogación de los datos fue el núcleo de mi presentación.
Avances en metadatos y calidad de datos para mayores eficiencias
He estado realizando la gestión de datos para grandes empresas e instituciones financieras durante la mayor parte de mi carrera, y ha sido muy interesante ver cómo se adoptan las oleadas de innovación técnica y cómo son exitosas o no tan exitosas en diferentes instituciones. Por esta razón, tenemos que explorar estas olas para el éxito y el fracaso preguntando; ¿Qué son los drivers? ¿Cuáles son los impulsores comerciales detrás de los datos y los metadatos? ¿Es esto interno o externo? Forrester Research arroja algo de luz sobre estas cuestiones.
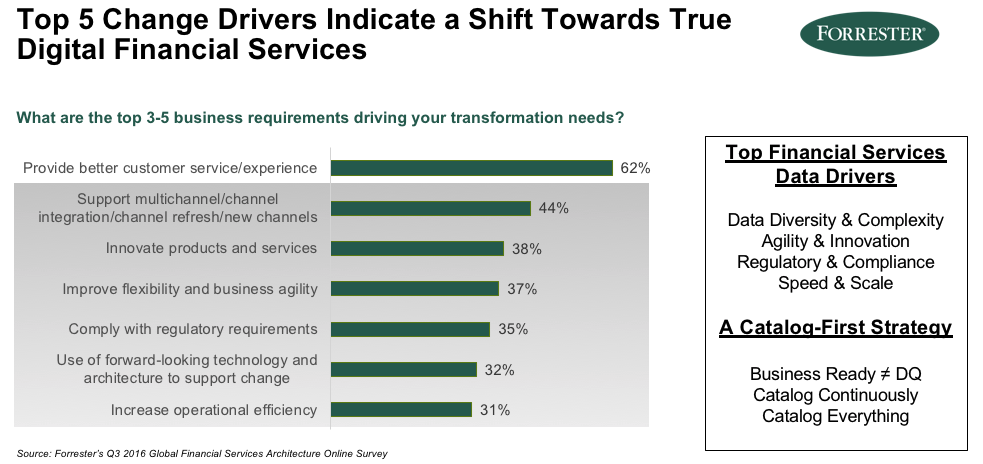
Uno de nuestros clientes, un banco al que no tengo permiso para nombrar públicamente, no tiene sucursales; un tipo de modelo de negocio muy diferente al de los bancos tradicionales y las compañías de gestión de inversiones Del mismo modo, también estamos viendo esto en la industria de seguros. Este gráfico de Forrester muestra que hay muchas iniciativas en marcha que intentan hacer esta transformación y, por supuesto, los principales impulsores son la experiencia del cliente.
Sin embargo, los que están por debajo de la experiencia del cliente, a saber, la integración de canales múltiples, la innovación en productos y servicios, la flexibilidad, la agilidad, son en realidad muy dependientes de los datos y metadatos, y de saber lo más posible sobre sus activos de datos. Aquí, los controladores de datos están ahora en torno a la diversidad y complejidad de los datos. Tienes IoT, tienes en línea, tienes datos semiestructurados, no estructurados, y la complejidad de unirlos todos para obtener una imagen holística.
Las empresas deben tener pistas de auditoría y los equipos de datos deben poder administrar y comprender sus activos de datos para lograr una mayor velocidad y escala. Estos controladores de datos obligan a lo que nos referimos a Podium como "una estrategia centrada en el catálogo" o "una estrategia de catálogo primero". Y la razón por la que hablamos de que es lo primero es que creemos que es absolutamente fundamental para entregar la automatización y la escala.
También creemos en la catalogación continua, que esto no es un esfuerzo de una sola vez o intermitente. Esto tiene que estar incorporado en los procesos y algo, un poco más radical es catalogarlo todo. Hablaré un poco sobre eso.
Una primera estrategia de catálogo
Exploremos más a fondo esta idea de catálogo primero. Una de las cosas que hemos encontrado es que cada vez hay más tecnologías que pueden escanear su universo y analizar sus datos y crear lo que llamamos un "catálogo de datos inteligentes".

El Catálogo inteligente debe ser capaz de manejar datos que no provienen de una fuente de almacenamiento de datos perfecta, pero los datos sin procesar que obtiene de un sistema telemétrico, un formulario web o un tercero, y lidiar con formatos complejos, datos sucios , etc. Creemos que el catálogo, desde el principio, debe ofrecer valor a través del perfilado automatizado de datos e identificar cosas como datos confidenciales. Este tipo de tecnología permite a las empresas construir un catálogo de datos rico y robusto, sin importar dónde se encuentre. Además, utiliza los datos y los metadatos que se derivan de eso, para comenzar a desarrollar su estrategia de datos porque si va a catalogar una gran cantidad de datos, no va a ser ingeniería y perfeccionarlos, pero sí Necesitará saber dónde está y qué es.
Por ejemplo, si tiene tres o cuatro fuentes del mismo tipo de información de transacción, querrá elegir la mejor fuente. Pero creemos que un catálogo automatizado lo ayudaría a usar eso como una herramienta de soporte de decisiones; "¿Cuál de estos deberíamos usar, y cuáles deberíamos preparar los negocios?"

Y utilizamos "business ready" como un término muy deliberado, que no es lo mismo que la calidad de los datos o los datos maestros. Esos son los polos extremos. En mi opinión, la calidad es apta para el propósito. Requiere cierta limpieza y conformidad de los datos, por lo que puede, por ejemplo, usarlo para análisis de marketing donde no tiene que ser 100% correcto para que pueda obtener una buena perspectiva. Por otro lado, si está realizando informes regulatorios o informes orientados al cliente, tiene que ser perfecto. Aquí, el grado de esfuerzo e ingeniería que usted pone para identificar la estructura de datos y prepararla difiere. Y para habilitar la agilidad, desea admitir múltiples tipos de preparación comercial. Un científico de datos puede usarlo en un recinto de seguridad rápidamente y los datos confidenciales siempre están protegidos.
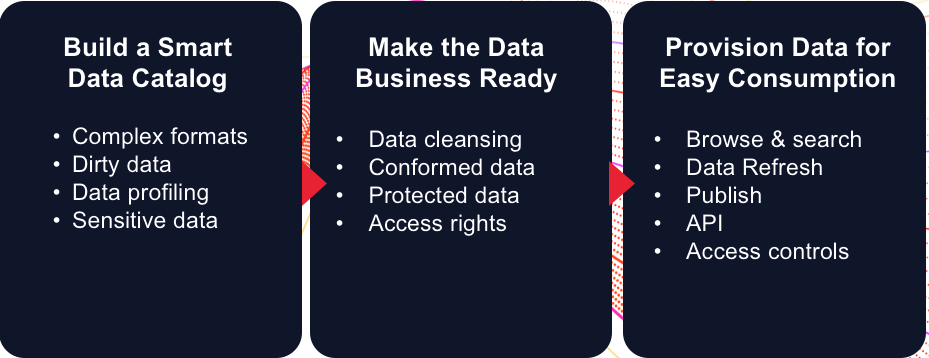
Y por último, el aprovisionamiento. Los datos deben ser como una experiencia de compra de Amazon. Deberíamos poder actualizarlo, examinarlo y buscarlo, publicarlo en otros sistemas, interactuar con los datos, los metadatos y el catálogo a través de las API, y al mismo tiempo respetar los controles de acceso.
En resumen
Nuestra visión de este catálogo para la estrategia requiere algunas nuevas tecnologías, como analizadores y analizadores de datos y herramientas de creación de perfiles. Algunos de ellos ya residen en la plataforma Podium, pero creo que, como principio general, es una buena práctica.
Catalogue continuamente y genere el mantenimiento de metadatos en sus procesos de software automatizados. Por lo tanto, mientras crea un catálogo y trae datos de origen, también está introduciendo metadatos.
¿Qué fuentes debemos migrar? ¿Dónde hay datos GDPR y PII? ¿Qué datos duplicados y relacionados debemos racionalizar? ¿Cuál es el perfil, contenido y calidad de cada campo?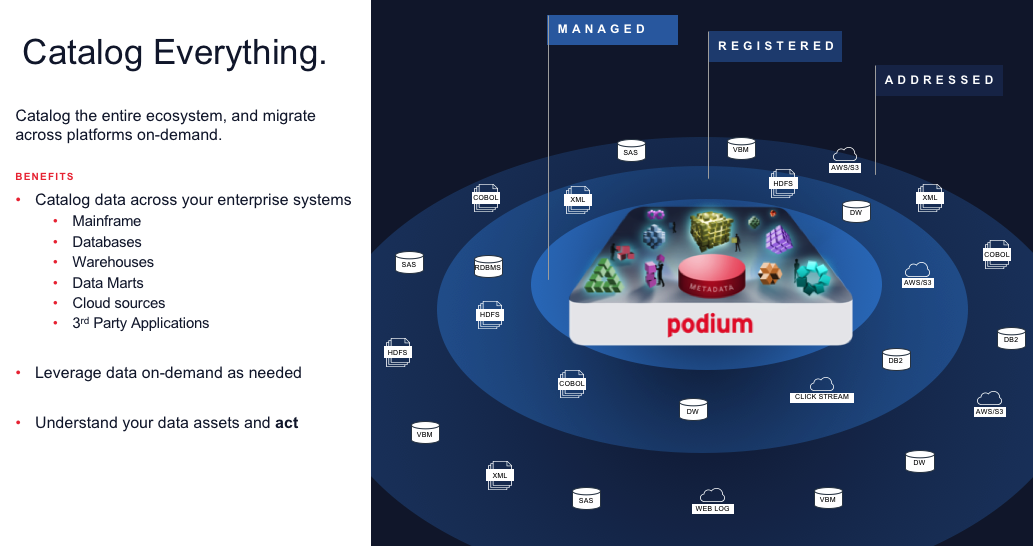
Tenga cuidado con las exageraciones en los lagos de datos y poner todo en un clúster. Las plataformas futuras que estamos viendo son que los datos van a residir en el lugar que mejor se ajuste a ellos. Y los datos pueden tener un plazo de vida en el que deberían estar en una nueva plataforma durante algunos años, o durante algunos meses, o tal vez solo un día. Puede estar afuera en la nube. Aquí es donde la catalogación independiente de la ubicación lo ayudará a adaptarse a las tecnologías futuras.

Comentarios para esta entrada
Sección en desarrollo...