Los Data Lake basados en Hadoop son una de las tendencias más candentes en los grandes datos de hoy en día porque prometen proporcionar una visión dinámica de los datos de su empresa para mejorar el análisis. Sin embargo, esa promesa parece progresivamente inalcanzable cuando se considera que mantener los datos frescos y relevantes a menudo depende de la escritura manual y del uso de una colección muy dispar de herramientas de código abierto. Este artículo describe los muchos problemas asociados con el uso de una sola de esas herramientas (Apache Sqoop) para la ingestión de datos, y ofrece un enfoque práctico para aumentar fácilmente los lagos de datos con información de los sistemas empresariales.
Data Lake y criaturas del pantano
Los Data Lake construidos con tecnologías como el BlueLake de Datos han surgido como el principal principio de diseño sobre el que los arquitectos, analistas y científicos de datos abordan los casos de uso moderno, como la detección de fraudes, la comercialización de clientes en tiempo real y el análisis de tendencias.
Es fácil ver por qué. Los Data Lake ofrecen varias ventajas para el análisis de negocios cuando se comparan con soluciones tradicionales como el almacenamiento de datos. En primer lugar, los Data Lake son modulares para permitir que los diferentes motores de procesamiento como MapReduce o Spark procesen eficientemente los datos, ya sea por lotes o en tiempo real. En segundo lugar, la arquitectura de Hadoop está construida para escalar tanto vertical como horizontalmente. Se puede escalar fácilmente añadiendo más potencia de computación a los servidores existentes, o añadiendo más servidores a un conjunto de recursos. En tercer lugar, el Hadoop basado en la nube ha alterado para siempre la economía y las posibilidades del análisis de negocios. Puedes instanciar los sistemas, escalar hacia arriba y hacia abajo según los requerimientos del negocio, y sólo pagar por los recursos que consumiste. Hay tanta flexibilidad.
Sin embargo, las empresas deben encontrar una manera de capturar, cargar, almacenar y gestionar la información en los Data Lake para realizar todo el potencial y la promesa de la tecnología. Todos hemos escuchado las historias de horror en las que el Data Lake se deteriora y proporciona poco valor a sus usuarios, especialmente cuando la vida útil de los datos se acorta. No quieres que tu prístino lago de datos se convierta en un pantano de datos.
Todo el mundo ama a un cachorro libre. El atractivo de Apache Sqoop
El ecosistema apache reconoció la necesidad de datos recientes y lanzó un proyecto llamado Apache Scoop. Apache Sqoop se graduó con éxito de la Incubadora en marzo de 2012 y ahora es un proyecto Apache de alto nivel. Apache Sqoop proporciona una forma simple y económica para que las organizaciones transfieran datos en masa de las bases de datos relacionales a Hadoop. Es una solución ideal para las empresas que están empezando a explorar las iniciativas del Data Lake y hay mucho que les gusta. Apache Sqoop es gratuito, puede realizar cargas de datos completas e incrementales, soporta múltiples formatos de bases de datos, puede integrarse a Apache Oozie para la programación y puede cargar datos directamente en Apache Hive. Así que, ¿qué es lo que no me gusta?
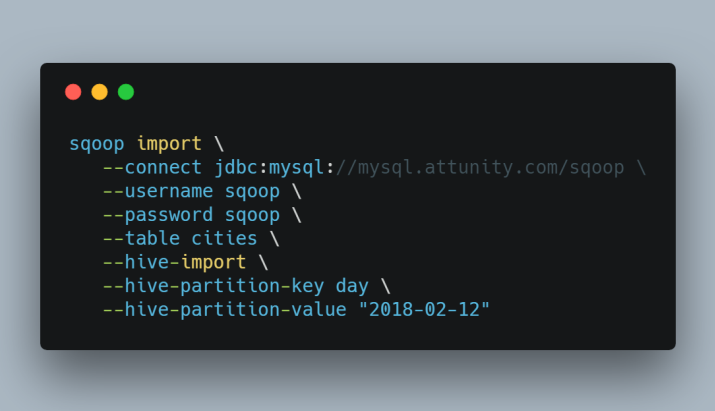
¿Un Sqoop o dos? Los desafíos de una solución libre
Apache Sqoop no tiene una interfaz gráfica de usuario, lo que podría considerarse como una pequeña molestia dependiendo de su opinión. Eso fue remediado en Apache Sqoop 2 que introdujo una aplicación web, una API REST y algunos cambios de seguridad. Sin embargo, Sqoop 1 y Sqoop 2 son incompatibles y Sqoop 2 no está aún recomendado para entornos de producción. Por lo tanto, cualquier Sqoop que decidas usar la interaccion sera en gran parte a traves de la linea de comandos. Un pequeño precio a pagar por la carga de datos de alta velocidad. Pero, usted sabía que Aquí había un pero que venía, ¿no es así? Llega un momento en la iniciativa Hadoop de todos en el que Apache Sqoop encuentra limitaciones prácticas al expandirse los despliegues. Los cuellos de botella en el rendimiento empiezan a afectar a la frescura de los datos y Apache Sqoop se ralentiza.
Para aumentar el rendimiento, Apache Sqoop utiliza trabajos de MapReduce llamados "mappers". Usar mas mapeadores llevara a un mayor numero de tareas de transferencia de datos concurrentes, lo que puede resultar en una mas rapida terminacion del trabajo. Sin embargo, también incrementará la carga de la base de datos ya que Sqoop ejecutará más consultas concurrentes. Aumentar el número de mapeadores no siempre conducirá a una finalización más rápida del trabajo. Mientras se incrementa el número de mapeadores, hay un punto en el que saturará completamente la base de datos. Aumentar el número de mapeadores más allá de este punto no conducirá a una finalización más rápida del trabajo; de hecho, tendrá el efecto opuesto, ya que su servidor de base de datos pasa más tiempo cambiando de contexto que sirviendo datos. Vale la pena señalar que cuando esta situación se presente, entonces otras consultas que se ejecuten en su servidor podrían verse impactadas, afectando adversamente su entorno de producción.
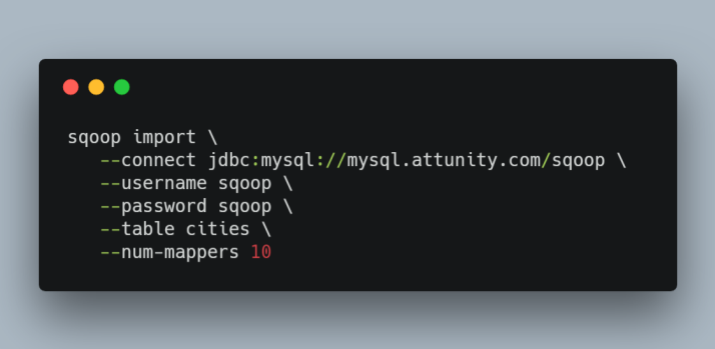
¿Un Sqoop o dos? Los desafíos de una solución libre.
La siguiente pregunta es: "¿Adónde puede acudir para recibir consejos de configuración y afinación?" Si estás usando una distribución Hadoop de uno de los principales proveedores como Cloudera, Hortonworks o MapR y tu suscripción está al día, entonces puede que tengas suerte de que te den soporte. Pero, si estás usando el proyecto gratuito Apache.org, entonces estás solo y es probable que pases horas de investigación buscando respuestas en la web. Puede que pienses que soy alarmista, pero un reciente documento de TDWI informó de que cerca de un tercio de los encuestados estaban preocupados por la falta de conocimientos de Hadoop y de herramientas de integración de datos (fuente: Data Lakes: Purposes, Practices, Patterns and Platforms. TDWI, 2017).
Por último, el último gran inconveniente de Apache Sqoop es "¿qué pasa con la carga de datos de otras fuentes empresariales? Por ejemplo, tal vez quiera cargar datos que se originen en una aplicación mainframe, o datos del sistema SAP o de telemetría de dispositivos de IO. ¿Es eso posible con Sqoop? No es fácil. Una eventual solución requeriría trabajo, como muchos volcados de archivos o carga de datos en y desde bases de datos intermedias. Feo, lento y propenso a errores, seguro. Esa no es una receta ganadora para tu moderno entorno analítico.
Attunity Replicate - Hemos hecho el trabajo duro para que usted no tenga que hacerlo.
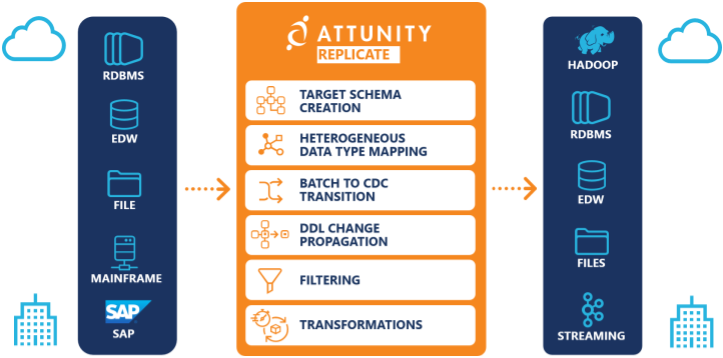
Replicación de la atención - Hemos hecho el trabajo duro para que usted no tenga que hacerlo. No voy a enfatizar demasiado los beneficios de la Attunity Replicate porque hay un sitio web entero dedicado a hacer eso, pero basta con decir que puede obtener más valor de su lago de datos sin necesidad de toda esa programación y afinación manual. La solución combinada pone los datos de la empresa justo en el corazón de su moderno entorno analítico y estará analizando los datos en poco tiempo.
¿Un Sqoop o dos? Los desafíos de una solución libre.
Con Attunity Replicate, puede fácilmente ingerir, replicar y sincronizar datos a través de su lago de datos y todas las principales bases de datos y almacenes de datos, ya sea en las instalaciones o en la nube.
Si aún no te he convencido de que superarás a Sqoop, entonces déjame también resaltar algunos "trucos" técnicos a considerar cuando intentes escalar un Apache Sqoop "listo para producción". Mira la tabla de abajo:
| Apache Sqoop | Attunity Replicate | |
|---|---|---|
| Estilo arquitectónico | Genérico basado en la consulta
Requiere disparadores o tablas con marcas de tiempo. Apaches Sqoop sólo captura inserciones/actualizaciones. No puede capturar borrados. |
El registro de transacciones nativas se basa en
Utiliza el registro nativo de transacciones para identificar los cambios y aprovecha al máximo los servicios y la seguridad que proporciona la base de datos. |
| Se requiere la aplicación y la modificación de la base de datos | Altamente intrusivo
Requiere marcas de tiempo. O bien se actualizan las aplicaciones y bases de datos si no existen o se necesita una representación consistente en todas las fuentes de datos. Esto introduce un tiempo de desarrollo y un riesgo significativo en su despliegue. |
No intrusivo
No requiere la instalación de software en la base de datos de la fuente, el nodo o el grupo Hadoop. |
| Gastos generales de los sistemas operativos | Recursos intensivos
Requiere una importante utilización de E/S y CPU ya que las consultas se realizan continuamente contra las tablas de origen. |
Recursos mínimos
Identifica los cambios en las transacciones desde el registro nativo de transacciones con un mínimo de gastos generales. |
| DDL / Cambios en el esquema | No hay CDC para el DDL/Cambio de esquema
Aunque Apaches Sqoop puede cargar metadatos en Apache Hive no captura ningún cambio en el DDL. Existe un riesgo significativo de que la aplicación se rompa cuando se produzcan cambios en el esquema, lo que requiere más esfuerzo de desarrollo, recursos y tiempo. |
Esquema consciente
Detecta automáticamente los cambios en el esquema de origen e implementa automáticamente los cambios en el objetivo. |
| Latencia | Alta latencia
Las esperas de los intervalos de consulta especificados; el tiempo de ejecución de las consultas; las demoras causan problemas de sincronización de los datos. Sqoop no puede ser pausado y reanudado. Es un paso atómico. Si falla, necesitas aclarar las cosas y empezar de nuevo. |
Baja/sin latencia. Tiempo real
Entrega inmediata de datos sin necesidad de almacenamiento intermedio. |
Actuación | Escalabilidad limitada
Como se mencionó anteriormente, Sqoop puede ser lento para cargar los datos y está hambriento de recursos porque utiliza MapReduce bajo el capó. La extracción incremental también es difícil porque las diferentes tablas requieren que se escriban consultas de extracción incremental. |
Escalabilidad lineal
La arquitectura multiservidor y multihilo soporta entornos de gran volumen y rápido cambio. Múltiples centros de datos, servidores y tareas pueden ser administrados y optimizados de forma centralizada con Attunity Enterprise Manager. |
Expandiendo su lago de datos - ¡a Apache Sqoop y más allá!
Ingerir datos en un lago de datos basado en Hadoop es sólo el principio y TI a menudo lucha por crear almacenes de datos analíticos utilizables. Los métodos tradicionales requieren que los programadores ETL conocedores de Hadoop codifiquen manualmente varios pasos - incluyendo la transformación de datos, la creación de estructuras Hive SQL, y la reconciliación de datos, y la carga administrativa a menudo puede retrasar o incluso matar los proyectos de análisis.
Attunity Compose for Hive automatiza la creación y carga de estructuras Hadoop Hive, así como la transformación de datos empresariales. Nuestra solución automatiza completamente la tubería de datos de BI en el Hive, permitiéndole crear automáticamente tanto Almacenes de Datos Operacionales (ODS) como Almacenes de Datos Históricos (HDS). Además, aprovechamos las últimas innovaciones de Hadoop, como las nuevas capacidades ACID Merge SQL, para procesar de forma automática y eficiente las inserciones, actualizaciones y eliminaciones de datos.
Attunity Replicate se integra con Attunity Compose for Hive para simplificar y acelerar la ingesta de datos, el aterrizaje de datos, la creación de esquemas SQL, la transformación de datos y la creación/actualización de ODS y HDS. Y, definitivamente no puedes hacer eso con Sqoop!
Conclusión
Los lagos de datos han surgido como una plataforma primaria en la que almacenar y procesar de forma rentable una amplia variedad de tipos de datos, sin embargo, mantener los datos frescos y relevantes puede ser extremadamente complejo, especialmente si no se ha considerado una estrategia de carga de datos. Apache Sqoop es un gran lugar para comenzar sus experimentos de ingestión de datos, pronto se dará cuenta de que no es realmente una solución de "grado empresarial", especialmente a medida que su despliegue se expande a más fuentes de datos, nodos y ubicaciones geográficas. El mejor consejo es aumentar el uso de Apache Sqoop con una solución probada como Attunity Replicate para acelerar y automatizar su tubería de carga de datos.
Próximos pasos
Regístrese para experimentar una versión de prueba gratuita del galardonado Attunity Replicate, una plataforma unificada que le ayuda a cargar e ingerir datos en todas las principales bases de datos, almacenes de datos y Hadoop, en las instalaciones o en la nube.

Comentarios para esta entrada
Sección en desarrollo...